Text-driven video editing aims to modify video content according to natural language instructions.
While recent training-free approaches have made progress by leveraging pre-trained diffusion models, they typically rely on inversion-based techniques that map input videos into the latent space, which often leads to temporal inconsistencies and degraded structural fidelity.
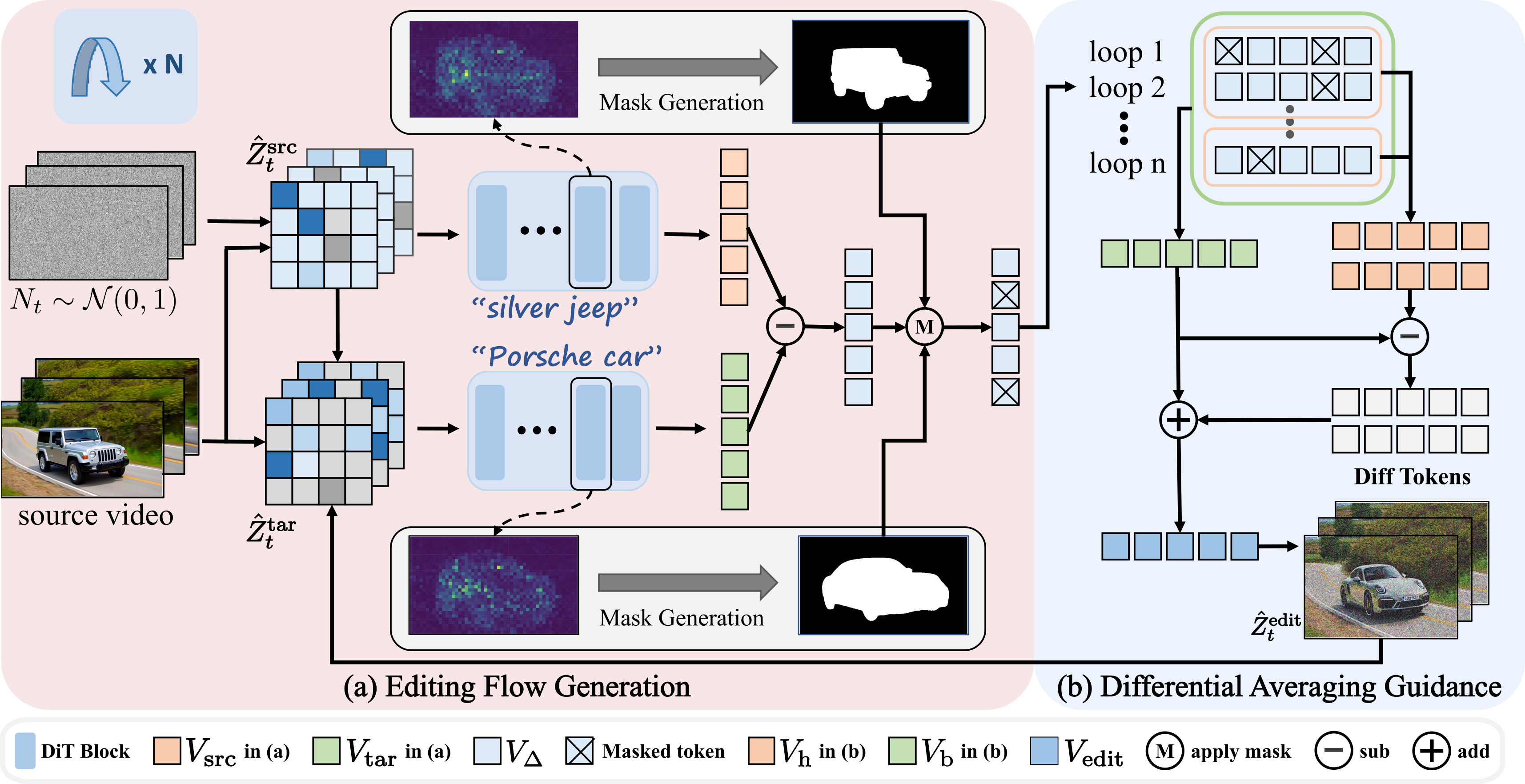
To address this, we propose FlowDirector, a novel inversion-free video editing framework.
Our framework models the editing process as a direct evolution in data space, guiding the video via an Ordinary Differential Equation (ODE) to smoothly transition along its inherent spatiotemporal manifold, thereby preserving temporal coherence and structural details.
To achieve localized and controllable edits, we introduce an attention-guided masking mechanism that modulates the ODE velocity field, preserving non-target regions both spatially and temporally.
Furthermore, to address incomplete edits and enhance semantic alignment with editing instructions, we present a guidance-enhanced editing strategy inspired by Classifier-Free Guidance, which leverages differential signals between multiple candidate flows to steer the editing trajectory toward stronger semantic alignment without compromising structural consistency.
Extensive experiments across benchmarks demonstrate that FlowDirector achieves state-of-the-art performance in instruction adherence, temporal consistency, and background preservation, establishing a new paradigm for efficient and coherent video editing without inversion.